Why your RAG demo doesn't survive production
A working LLM prototype and an enterprise-grade RAG system are separated by a body of unglamorous infrastructure: evals, guardrails, observability, cost controls, drift detection. Here's the checklist we use to close the gap.

We've shipped a lot of RAG systems in the last 18 months. Roughly one in three started as a working prototype somewhere else, sometimes inside the client's own team, sometimes from another vendor. They worked beautifully in demos and fell over in production.
The gap is not model selection. It's not chunking strategy. It's not even prompt engineering. It's the invisible body of infrastructure that turns a clever pipeline into a system you can sell to enterprise customers without losing sleep.
Here's the checklist we work through on every AI-Native engagement.
1. Evals come before anything else
If you can't measure quality, you can't ship quality. The first artifact on a Hexcore AI engagement is not a prototype — it's an eval set:
- 100–300 representative queries with reference answers (or rubric criteria for open-ended outputs)
- A scoring function that runs offline and reproducibly
- Baselines from the simplest possible system (BM25, single-LLM-call) so you know what "good" means
We run this eval at every major change. If a model swap, a chunking change, or a prompt revision doesn't move the eval, it didn't ship value — and we revert it.
2. Retrieval is where most quality lives
Most failed RAG systems failed in retrieval, not generation. The model couldn't answer because the context never had the right passages.
Investigate, in this order:
- Chunking strategy: Are chunks split on semantic boundaries (sections, paragraphs) or arbitrary token counts? The latter shreds context.
- Embedding choice: Domain-specific embeddings (e.g., legal, medical) usually beat general-purpose by 8–15% recall@10.
- Hybrid retrieval: Combining BM25 + dense retrieval with rank fusion almost always beats either alone for technical domains.
- Reranking: A cross-encoder reranker on the top-50 → top-5 is often the single biggest quality lever and runs in
<100ms.
3. Guardrails are not optional once you have customers
Every production RAG needs, at minimum:
- Input filtering: PII detection, prompt-injection patterns, off-policy queries
- Output filtering: PII leak detection on responses, hallucination flags on low-confidence retrievals
- Refusal handling: Graceful "I can't answer that" paths, with telemetry on refusal rate
- Rate limits: Per-tenant, per-user, per-query-cost-tier
You will not think you need all of these. You will need all of these the first time you onboard a regulated-industry customer.
4. Observability for AI is different
Standard APM tells you latency and error rate. AI observability needs to tell you quality:
- Token costs per query, per tenant, per feature
- Retrieval hit-rate (was anything relevant returned?)
- Refusal rate (is the model dropping queries it should answer?)
- User feedback signals (thumbs, edits, abandons)
- Drift detection: is eval score trending down over time?
The teams who skip this learn, three months in, that their quality has been steadily degrading and no one noticed because the system was still "working."
5. Cost controls live next to the prompt
LLM costs scale in ways traditional infra doesn't. A 3× spike in usage at 10× the per-query cost is a routine bill shock. Bake in:
- Per-tenant token budgets with hard cutoffs
- Model routing: cheap model for simple queries, expensive model only when needed
- Caching: response cache for deterministic queries, embedding cache for repeated passages
- Streaming termination: cut off generation when the answer is found
Done right, this halves the bill before you've optimised a single prompt.
6. Human-in-the-loop is a feature, not a fallback
For high-stakes domains (legal, medical, finance), the question is not whether humans review outputs but how — efficiently. We build:
- A reviewer queue surfacing low-confidence or refused outputs
- A consistent annotation interface so reviewers' feedback flows back to evals
- A drift signal when reviewer correction rates increase
This loop is the difference between "shipped a demo" and "operating a regulated AI product."
7. Versioning everything
Prompts, retrieval configs, model selections, eval sets — all versioned, all tied to the deployment that ran them. When quality regresses six months from now, you need to be able to answer: what changed?
We use a prompt registry (a thin layer over Git) so every production query references a specific prompt SHA. Reproducibility is not optional in regulated contexts.
The honest summary
A RAG demo is a 3-day project. A production RAG system is a 10–20-week project. The visible work — model selection, prompt engineering, chunking — is maybe 20% of that. The other 80% is the infrastructure above.
This is why most "we'll integrate AI ourselves" projects stall after the prototype: the team built the visible 20% and then ran out of road. The remaining 80% is engineering systems work that requires conviction, not novelty.
If you're moving an AI feature from prototype to production, the right question to ask is not "is the model good enough?" It's "can we measure it, observe it, contain its cost, and operate it under load?" If the answer to any of those is no, that's where the next sprint goes.
We've made each of these mistakes ourselves. The checklist is what we wish someone had handed us in 2023.
15 years across payments, telco, and platform engineering. Founded Hexcore to prove African engineering can ship at world-class standards.
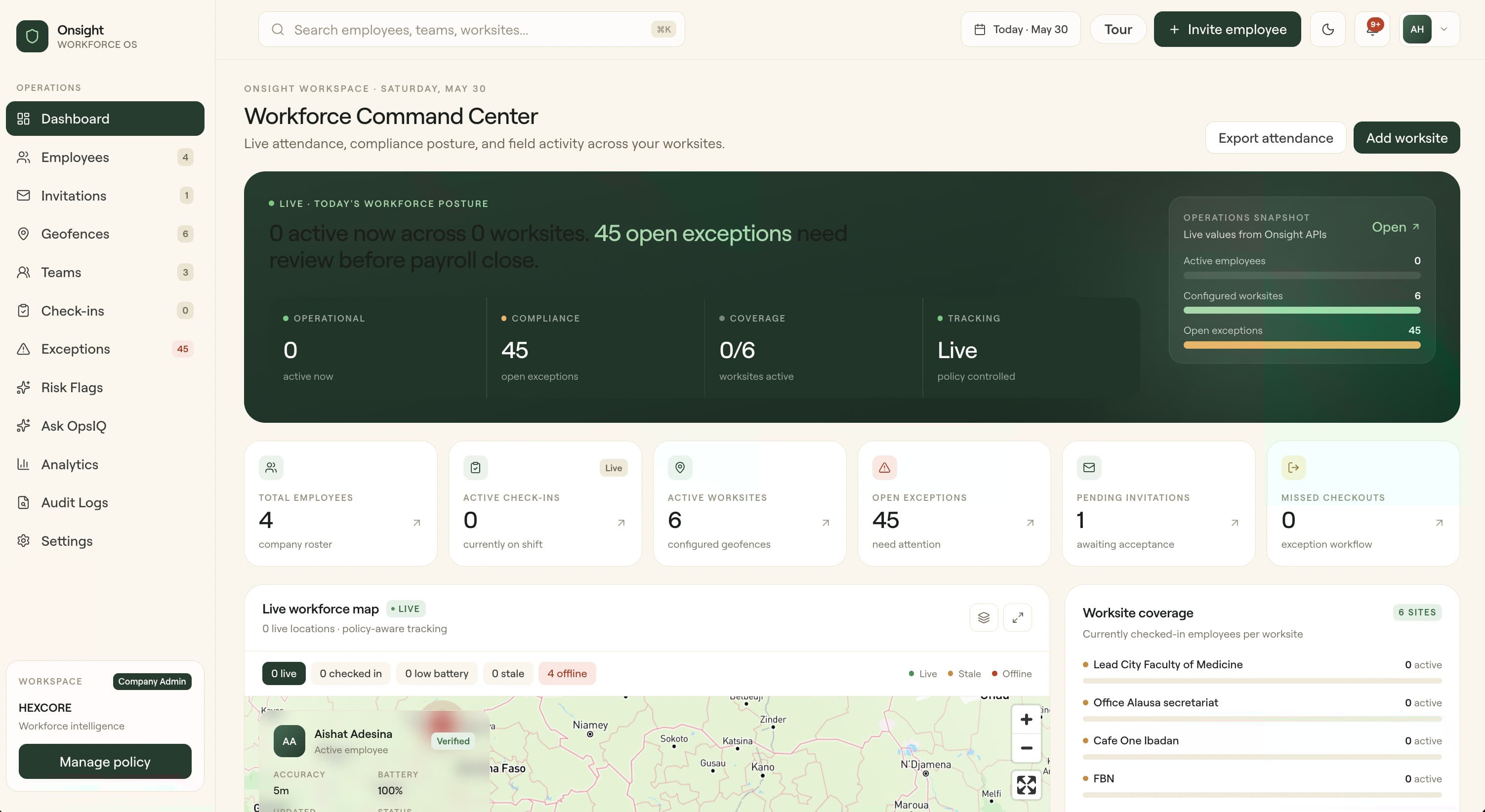
Shipping Onsight: lessons from building workforce intelligence at field scale
Onsight is a workforce intelligence platform we built end-to-end at Hexcore — admin dashboard, native mobile app, exception queue, and the OpsIQ AI command layer. Here's what we learned shipping a four-surface product to teams operating in tough field conditions.

Microservices aren't a scaling strategy
Microservices solve an organisational problem, not a performance problem. Reach for them when your team structure demands it — not because your traffic does. Here's how we decide, what goes wrong when teams decide wrong, and the boring monolith pattern we ship instead nine times out of ten.

The four practices that turn a launch into a durable product
Most launches succeed. Most products fail soon after. The gap is not engineering talent — it's a set of operating practices that the strongest teams treat as defaults. Here are the four we install on every Hexcore engagement.